Copying tables from PDFs to Excel can be a nightmare. Wonky formatting, lost data, and inconsistencies can make you want to pull your hair out. It's a chore nobody wants to do, especially when dealing with complex tables, inconsistent layouts, multiple languages, and unstructured data.
You know you're in for a tough time when you see those 'Please find attached' emails in your inbox featuring PDFs with tables upon tables of data that you need to transfer to a spreadsheet. Whether the document in question is an invoice, PO, customer order, expense claim, or report, extracting data from PDFs and transferring it to a more analysis-friendly format like Microsoft Excel can be frustrating.
Thankfully, there are ways to make this process less painful. Let's explore 8 foolproof methods to convert PDF tables to Excel, from quick-and-dirty copy-paste to AI-powered OCR automation.
PDF → Excel in seconds!
Upload your PDFs or drag and drop them into our free PDF-to-XLSX converter, and within seconds, you'll have an editable spreadsheet ready to use.
Excel is the Swiss Army knife of data analysis. It lets you sort and filter data, create pivot tables and charts, apply complex formulas, and collaborate with team members.
PDFs, on the other hand, are static documents designed for viewing, not editing. While they preserve formatting across devices, PDFs limit your ability to manage and analyze data effectively.
By importing tables from PDF to Excel, you're not just moving data – you're unlocking trapped insights. So whether you're a number-crunching analyst or a busy manager drowning in reports, being able to handle PDF-to-Excel conversion efficiently can save you hours of tedious work and frustration.
| Method | Use Cases | Key Benefit |
|---|---|---|
| Copy PDF table to Excel manually | Occasional processing of simple, small tables from digital PDFs (e.g., reports, presentations, or data sheets) | No additional tools required |
| Google Docs/MS Word | Text-heavy digital PDFs with simple formatting (e.g., contracts, research papers, manuals) | Simple workflow |
| Adobe Acrobat Pro | Occasional processing of digital PDFs with tables, forms, or financial data (e.g., invoices, bank statements, tax forms) | Maintains original formatting |
| Excel's Get Data feature | Frequent processing of digital PDFs with simple, well-defined tables (e.g., price lists, inventory reports, sales data) | Built-in Excel feature |
| Online conversion tools | Occasional, small-scale conversions of digital PDFs with basic tables (e.g., product catalogs, price sheets, simple reports) | Fast and convenient |
| Open-source (Tabula, Excalibur) | Frequent processing of digital PDFs with consistent, well-structured tables (e.g., research data, financial reports, government documents) | Great for sensitive data |
| AI-powered OCR tools (Nanonets) | High-volume processing of digital or scanned PDFs with complex layouts (e.g., invoices, receipts, forms, reports) | Automated and scalable |
Sometimes, you may not have the time or permission to install or sign up for new software. You want to quickly transfer the PDF data into an Excel table and continue your work.
Here are a few different ways to do it:
Let's kick things off with the simplest approach to copy table from PDF to Excel spreadsheets. However, this method might not preserve the table's structure and almost always requires manual work to clean the data.
This method works if the data you need to extract from a PDF is relatively simple and small in volume.
Here's a quick step-by-step guide to copy and paste table from PDF to Excel:
The content will now be in Excel table. The formatting might be a bit wonky, so you may need to clean it up a bit.
Pro tip: Using a newer version of Excel? Look for the 'Use Text Import Wizard' when pasting. This handy feature lets you control how your PDF data lands in Excel. Specify whether the data is delimited (separated by tabs, colons, semicolons, spaces, or other characters) or fixed-width, choose the starting row for data import, select the character set and text qualifier, and preview the data before finalizing the import.
Keep in mind that manually copying tables, with or without the wizard, might not work so well with scanned images or PDFs with really intricate layouts. If you are dealing with bigger or more complex tabular data, check out the other methods discussed in this article.
You cannot manually copy PDF data to Excel tables if they are scanned images or documents with complex layouts. Consider one of the other methods discussed in the article for larger or more complicated tasks.
Note: If the PDF is read-only or password-protected, you may not have permission to select or copy the content. In such cases, you must first ask the PDF owner for the password or a copy of the PDF with the necessary permissions.
Google Docs and Microsoft Word now have built-in capabilities for opening and editing PDF files. This can be handy if you need to copy from PDF to Excel quickly.
To use Google Docs to copy data from PDF into Excel tables, follow these steps:
Pro tip: Merged cells and multi-line headers in PDF tables can cause formatting issues when imported into Excel, resulting in misaligned data. To fix this, use the Unmerge Cells (Found in Merge & Center dropdown in the Alignment group) feature to separate the merged cells and restore proper data organization.
To use MS Word as an intermediary to copy data from PDF into Excel, follow these steps:
In Excel, click on the 'Paste' menu to see more paste options. You can choose to match the destination formatting or keep the source formatting. Additionally, if you want to maintain a link to the original Word table, select 'Paste Link' in the Paste Special menu.
Google Docs and Microsoft Word have built-in OCR, which is great because you don't have to pay extra. But the output might not be perfect. You could end up with mixed-up paragraphs, misaligned images, and fields that aren't lined up right. So, be ready to spend additional time fixing and adjusting the formatting.
These tools struggle with complex tables, scanned images, and PDFs with intricate layouts. They work better for simpler, text-heavy PDF files.
Optical Character Recognition (OCR) is the process of converting printed or handwritten text into machine-encoded text. OCR software uses optical scanning technology to identify characters in a digital image and convert them into editable and searchable formats like TXT, DOCX, XLSX, CSV, JSON, and others.
Acrobat Reader Pro offers several built-in features for extracting tables from PDF to Excel. Firstly, convert PDF table to Excel using its 'Export PDF to' feature.
The steps involved in converting PDF to XLSX using Adobe Acrobat Reader:
This method works great if your PDF has simple, well-structured tables. However, the results may not always be perfect for scanned PDFs, complex tabular data, or multi-page tables. You might need to clean up before your data is ready to use. And since it doesn't support batch processing, you can only convert one PDF file to Excel at a time, which may not be ideal for larger tasks.
Another method is to use the 'Select text' feature. Using this tool, you can select and copy the table content from your PDF and paste it into Excel.
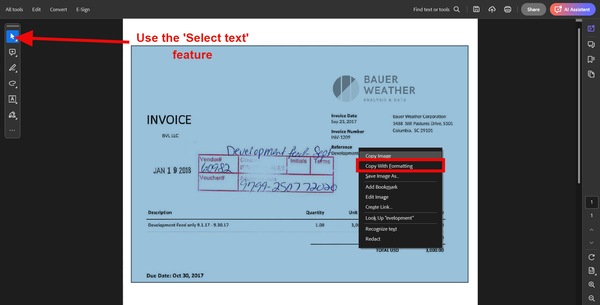
Note: These two features are not available with the free version of Adobe Acrobat Reader. You must purchase a license or subscribe to Adobe Acrobat Pro to access it.
Here's how to copy PDF tables with formatting using Adobe Acrobat Reader:
This method works even for scanned PDFs. Acrobat’s OCR technology can recognize and extract text from images. Since the workflow is relatively straightforward, it is an intuitive option for users who need to copy tables from PDF to Excel quickly.
Pro tip: Adobe Acrobat Reader Pro allows users to enhance the document to improve OCR accuracy. This is particularly helpful for scanned documents and low-quality digital PDFs.
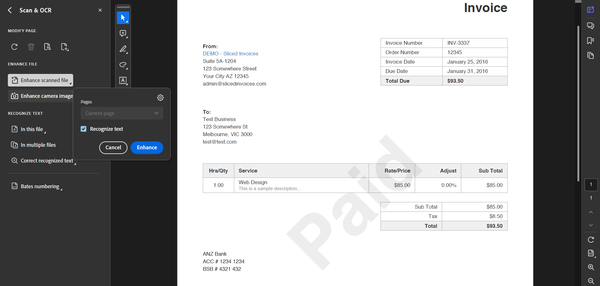
However, it can be time-consuming if you have multiple tables to extract or if the tables span multiple pages. It may also struggle with complex layouts or poor-quality scans. You might need to manually adjust the formatting and clean up the data before using it.
Adobe Acrobat also allows you to copy the content as an image. It can be handy if you want to preserve the original formatting or if the table contains complex elements that don't copy correctly as text. However, it may not be the best option if you need to edit or manipulate the data in Excel.
Let's face it, sometimes, you just need to copy a table from a PDF to Excel. No bells and whistles — you just need a straightforward solution.
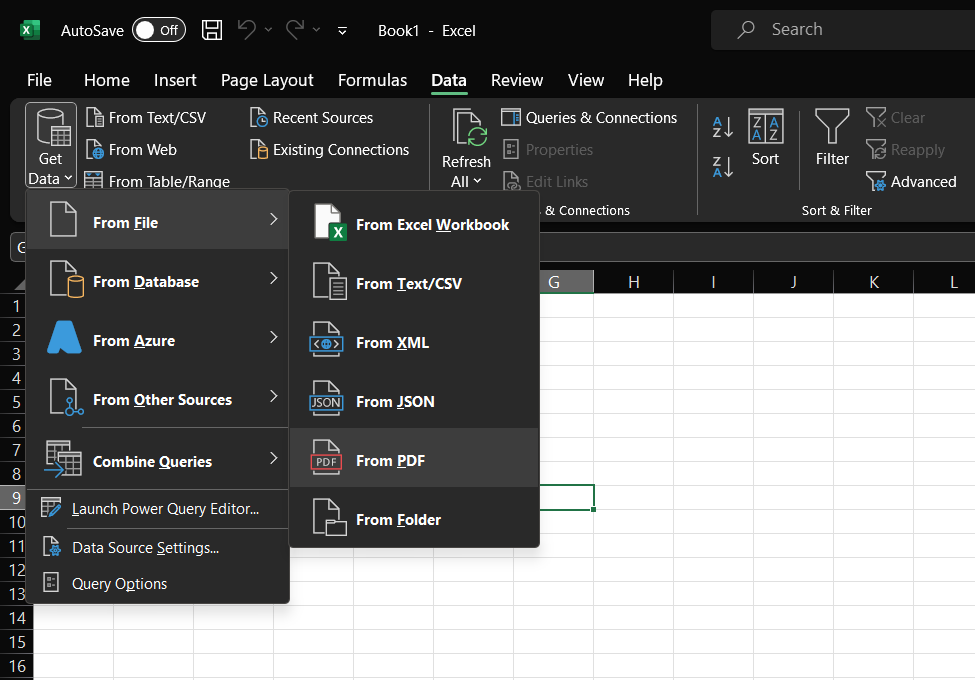
Microsoft Excel's Get Data feature is what you need. It is quick and easy. And you don't need any additional software.
Steps to use Excel's built-in PDF import option:
Pro tip: If you're pasting tabular data and it ends up all in one cell, you can use Excel's 'Text to Columns' feature to separate it into the right cells. It can be found in the Data tab in the Data Tools group. Simply follow the wizard to split your data into separate columns based on delimiters like spaces, commas, or tabs. You can also use it for tables with inconsistent formatting, with some cells containing extra spaces, line breaks, or other unwanted characters.
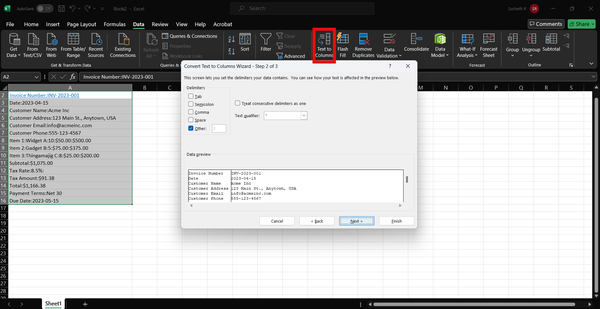
You have the option to select individual tables or all the tables present on a single page. Moreover, you can also transform the sheet using a Power Query editor. This editor allows you to adjust the data, like removing unnecessary columns or rows, splitting or merging columns, changing data types, filtering or sorting the data, and adding calculated columns.
Extract key data from invoice PDFs in seconds!
Capture invoice numbers, totals, and line items effortlessly. Integrate with your accounting software for streamlined bookkeeping! Simplify your data extraction workflows now.
There are many simple web-based conversion tools out there that can simplify the PDF table to Excel workflow. Whether you want the output in CSV, XLS, or XLSX format, these tools can manage it all.
All you have to do is upload the PDF. Let the tool process and convert the file. You can then download it in the spreadsheet format of your choice. The reliability, functionality, and accuracy of these tools can vary greatly, but they generally work well for simple tasks.
Here's how to convert PDF tables to Excel using online converters:
Most of these tools offer a free tier. But you might need to subscribe to their premium plans for more advanced features or to remove limitations. Remember that uploading sensitive information to these online tools might pose a security risk. Make sure to read their privacy policies before using them.
Despite being easy to use, these tools have their limitations. If you are dealing with complex tables, scanned or image-based PDFs, or multi-page tables, these online converters might not yield the best results. More importantly, these tools won't be adequate if you need to copy a large number of tables regularly or if you require batch-processing capabilities.
Prioritize data security with Nanonets' GDPR-Compliant OCR!
While online PDF to Excel converters might seem convenient, they can put your sensitive data at risk. Nanonets puts data security first, employing advanced encryption and adhering to GDPR and CCPA regulations. Process your documents with confidence.
📅 Get a Personalized DemoOpen-source software can provide powerful solutions for extracting tables from PDFs to Excel. These tools are free to use and can often handle more complex tasks than the abovementioned methods.
The best part is that you’ll have a great deal of control over your data and its security, as all processing is done locally on your machine.
If you are an open-source enthusiast, then Tabula is an excellent choice. This Java-based tool allows you to extract tables from PDF files and convert them into CSV or Microsoft Excel format.
Since it is a desktop application, you must download and install it on your computer. Then follow these steps to extract your PDF table into Excel:
Tabula works best for PDFs with simple and well-structured tables. It doesn't work on PDFs with scanned images or complex layouts, nor does it support batch processing. It may not be the best choice for copying large volumes of data or dealing with intricate table structures.
Excalibur might suit you if you are a tech-savvy individual who doesn't mind getting your hands dirty. Excalibur is a web interface for extracting tabular data from PDFs, built on top of Camelot, a Python library known for its high accuracy and speed.
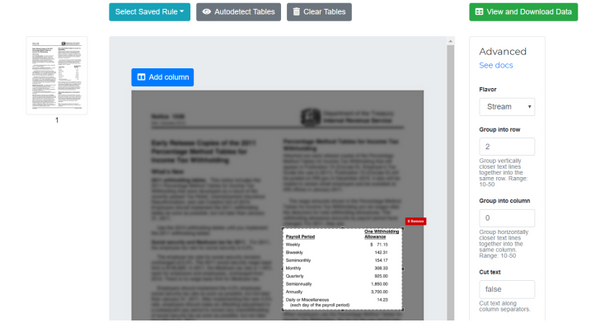
Follow these steps to use Excalibur to extract your PDF table into Excel:
Excalibur gives you control over the extraction process — allowing you to autodetect tables, export in multiple formats, and even fine-tune the extraction settings.
However, it requires technical knowledge and installation, which might not be suitable for everyone. It's also worth noting that, like Tabula, Excalibur might struggle with PDFs containing scanned images or complex tables and doesn't support batch processing.
Bonus: Here are some OCR tips to help you achieve the best results when dealing with scanned and low-quality PDFs:
☑️ Scan your documents at a high resolution (at least 300 DPI) to ensure clarity and detail.
☑️ If possible, scan in grayscale rather than black and white for better contrast and accuracy.
☑️ Make sure your scans are straight and aligned properly. Skewed or crooked scans can throw off the OCR process.
☑️ If the text in your PDF is low-contrast or hard to distinguish from the background, try using a PDF editing tool to adjust the brightness and contrast.
☑️ For low-quality digital PDFs, get the original file (Word document or Excel spreadsheet) and remake the PDF with better resolution and less compression.
☑️ Ensure that the OCR software is set to the appropriate language for the scanned text, as language-specific recognition can yield better results.
☑️ When creating digital documents, use standard, machine-readable fonts like Arial, Times New Roman, or Calibri to improve OCR accuracy.
The manual and semi-automated methods fall short when dealing with large-scale data extraction. If you have to extract tables from hundreds or thousands of PDFs, manual methods simply won't cut it.
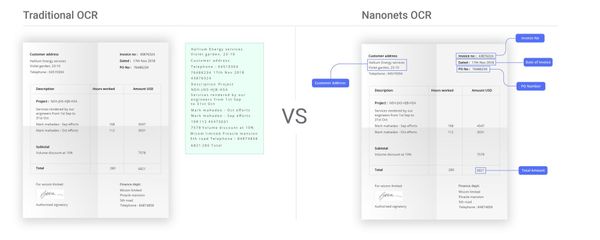
You'll need an automated solution that offers OCR and AI capabilities. It can accurately identify and extract tables from PDFs, regardless of the language, complexity, or layout – even scanned or image PDFs. Nanonets is a leader in this space, offering a powerful AI-based OCR tool that can handle all sorts of PDF processing with ease.
What makes Nanonets a great fit? For starters, it offers a free PDF-to-Excel converter tool that allows you to convert your documents in a few simple steps:

For more advanced features, use Nanonets' Table OCR solution. The model has been pre-trained on millions of documents and tested to ensure high accuracy and reliability out of the box. It allows you to automate even the most complex PDF to Excel workflows, from invoice processing to financial data extraction and beyond.
Here are the steps involved:
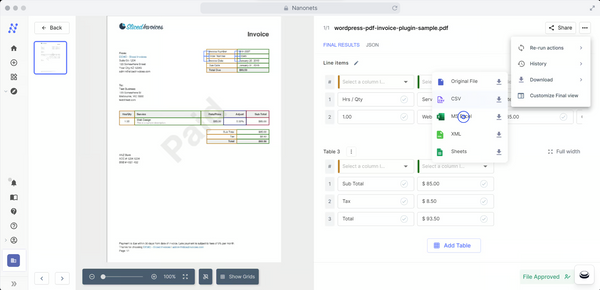
With Nanonets, you can:
You can streamline data extraction for a variety of document types and industries, including:
No matter what type of document you're working with, Nanonets can automate the extraction process and eliminate the manual entry of any tabular data. You don't need to be a tech whiz to use it, the interface is intuitive and requires no coding or special training. The platform supports API integration for custom workflows.
Let's look at a simple example. If you work in the accounts department and need to process invoices for the organization's tech tools, you may encounter invoices with varied layouts, structures, and formats. Manually checking each, copying data from tables, and inputting it into an Excel table for analysis can be a nightmare.
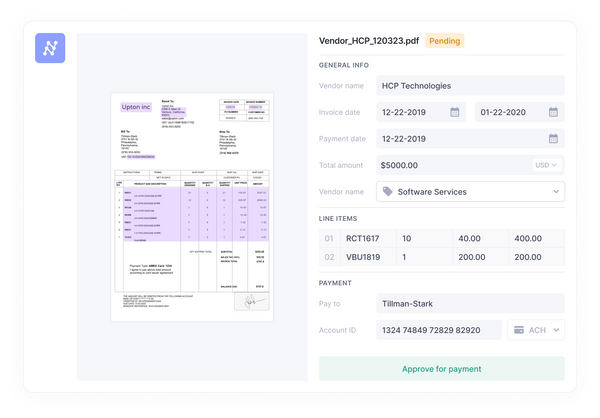
With the Nanonets PDF data extraction tool, upload invoices to automate processing. It identifies the layout, Key-Value Pairs, and extracts data fields like invoice number, date, vendor name, amount, etc. The information is compiled into a spreadsheet and exported to accounting software like QuickBooks. No more tedious data entry or inaccurate records.
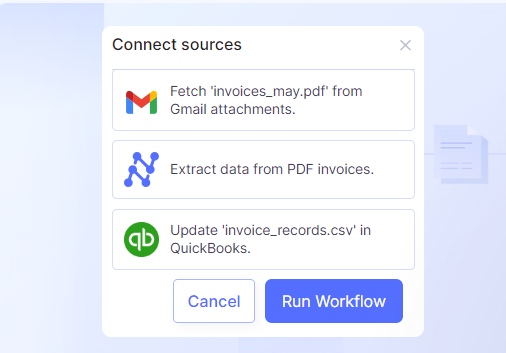
The tool learns from your edits. The AI processing gets smarter with each interaction, making future extractions more accurate. It can handle unstructured data or complex tables in PDFs.
Nanonets takes data security and privacy seriously. It uses advanced encryption to protect data during upload, processing, and storage. The platform is GDPR and CCPA-compliant, ensuring that sensitive information remains secure.
Here's hoping you won't have to look up how to transfer a table from a PDF file to Excel ever again. There is more than one way to handle this task. However, automation is undoubtedly the most efficient way to handle the task when dealing with large volumes of data.
The perfect method depends on what suits your specific scenario. Assess your tables' complexity and consider the volume and the time you're prepared to invest. After all, figuring out how to copy a table from PDF to Excel shouldn't be an arduous task.
Process thousands of PDFs in minutes!
Bulk extract text and data from thousands of structured and unstructured PDFs — while maintaining over 95% accuracy! Stop wasting time copying data between PDFs and spreadsheets. Automate the busywork so you can focus on what really matters. Want to see how our intelligent solution can transform your workflow?
📅 Claim Your Free Demo SlotNanonets is an AI-powered tool for extracting tables from PDFs. It can handle PDFs with complex layouts and unstructured data. Simply upload your PDF ,and Nanonets will automatically identify and extract the tables.
You can also use online conversion tools. For more control, try open-source tools like Tabula or Excalibur. These allow you to select the specific tables to extract.
Lastly, you can use Excel itself. Excel has a built-in PDF import feature that lets you extract tables from PDFs without additional software.
To copy a table from PDF to Excel without losing formatting, use an AI-powered tool like Nanonets. Simply upload your PDF, let the tool automatically extract the tables, and download the data in Excel format. This preserves the original table structure and formatting.
Alternatively, you can use Excel's built-in PDF import feature. Go to the Data tab and click Get Data > From File > From PDF. Select the PDF, choose the table to import, and click Load. This brings the table into Excel, typically with formatting intact.
Here’s how you can use Excel’s Get Data feature to copy a table from a PDF to Excel:
To copy an entire table from a PDF using Excel's Get Data feature, follow these steps:
Yes, you can extract tables from PDF files using several methods. The simplest is Excel's built-in feature: Data > Get Data > From File > From PDF. You can also use Adobe Acrobat Pro to export PDFs to Excel or try online conversion tools for quick, one-off extractions. For more control, open-source software like Tabula allows manual table selection. For complex layouts or bulk processing, automated AI-powered tools like Nanonets offer the most efficient solution, using advanced OCR to accurately extract tables from various PDF types, including scanned documents and unstructured data.
To import multiple tables from a PDF into Excel, you can use Nanonets’ automated extraction tool. Follow these steps:
Here's how to copy PDF tables with formatting using Adobe Acrobat Reader: